vscode配置C++开发环境
本文共 2395 字,大约阅读时间需要 7 分钟。
之前写的细节方面还是有点问题——2020.7.3更
昨天从下午一直研究到晚上十一点,查阅了很多博客资料,还是没配置好vscode的C++编译环境,今天早上又弄了一下,现在OK了。
虽然很多东西的原理不懂,但是现在知道这样就行了,以后用多了应该会慢慢熟悉。
第一步,先去官网下载vscode。安装在自己想要的位置即可。
第二步,去官网下载MinGW。安装在自己想要的位置即可。
进入网站后不要点击 "Download Lasted Version",往下滑,找到最新版的 "x86_64-posix-seh"下载。
第三步,配置MinGW环境变量。
1.复制MinGW路径(详见第6点)。
2.打开控制面板、搜索高级系统设置并进入。
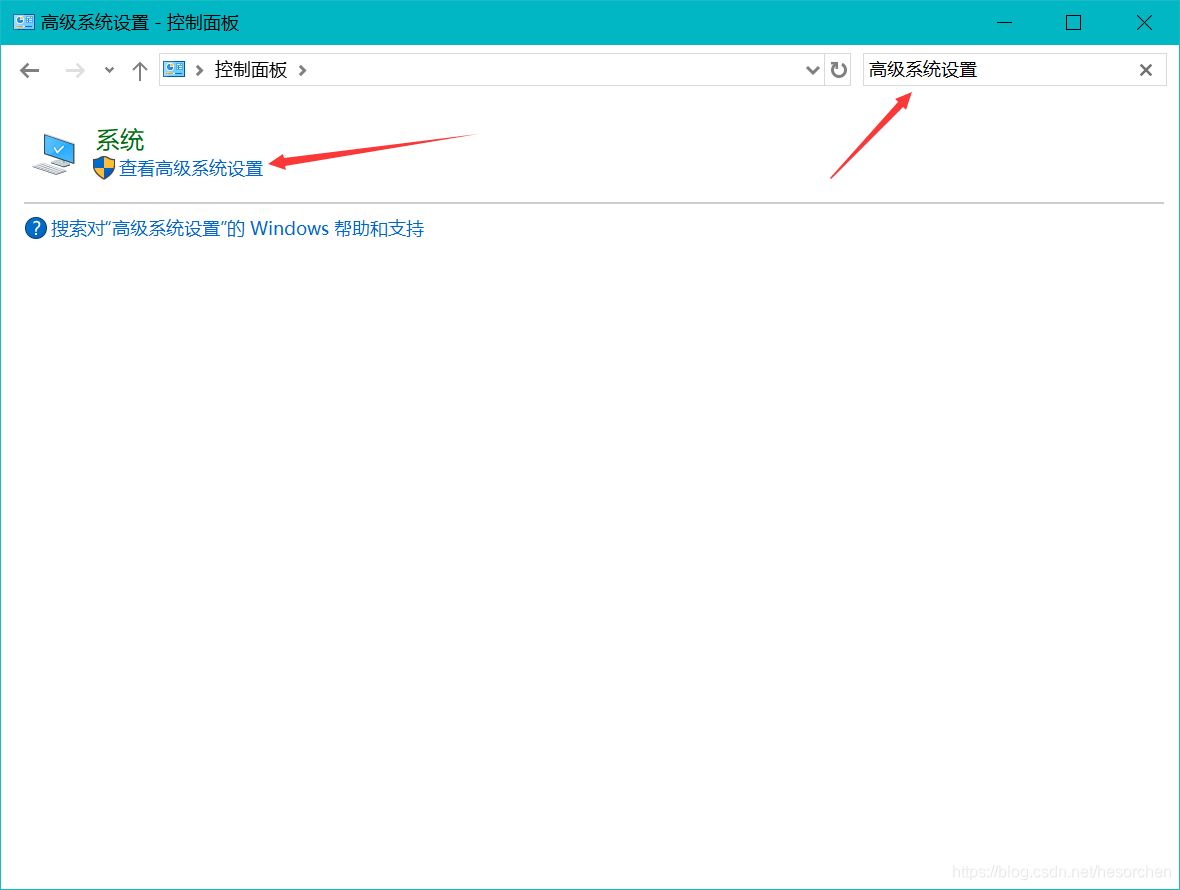
3.点击环境变量。
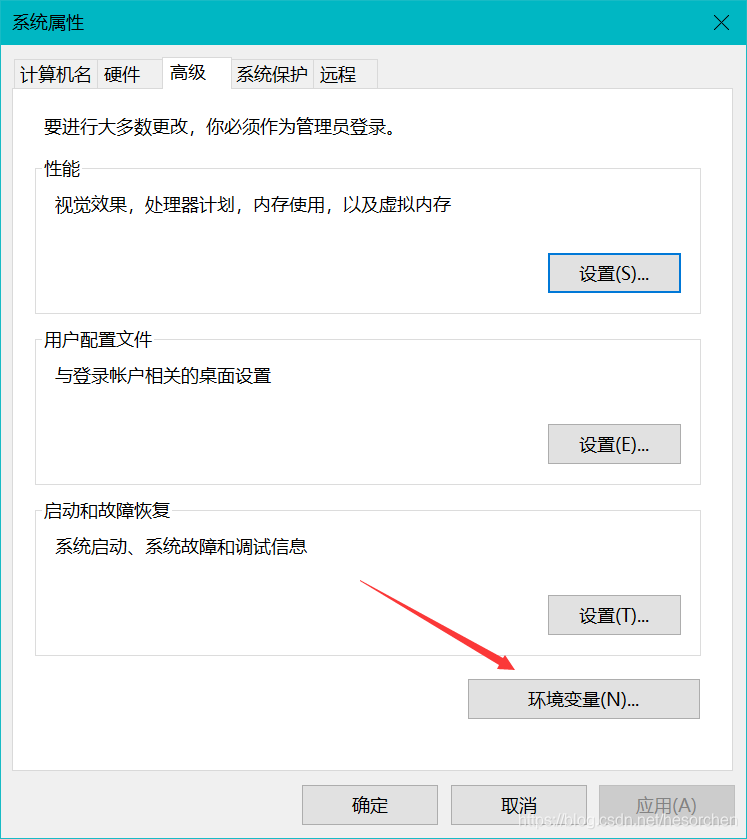
4.双击Path。
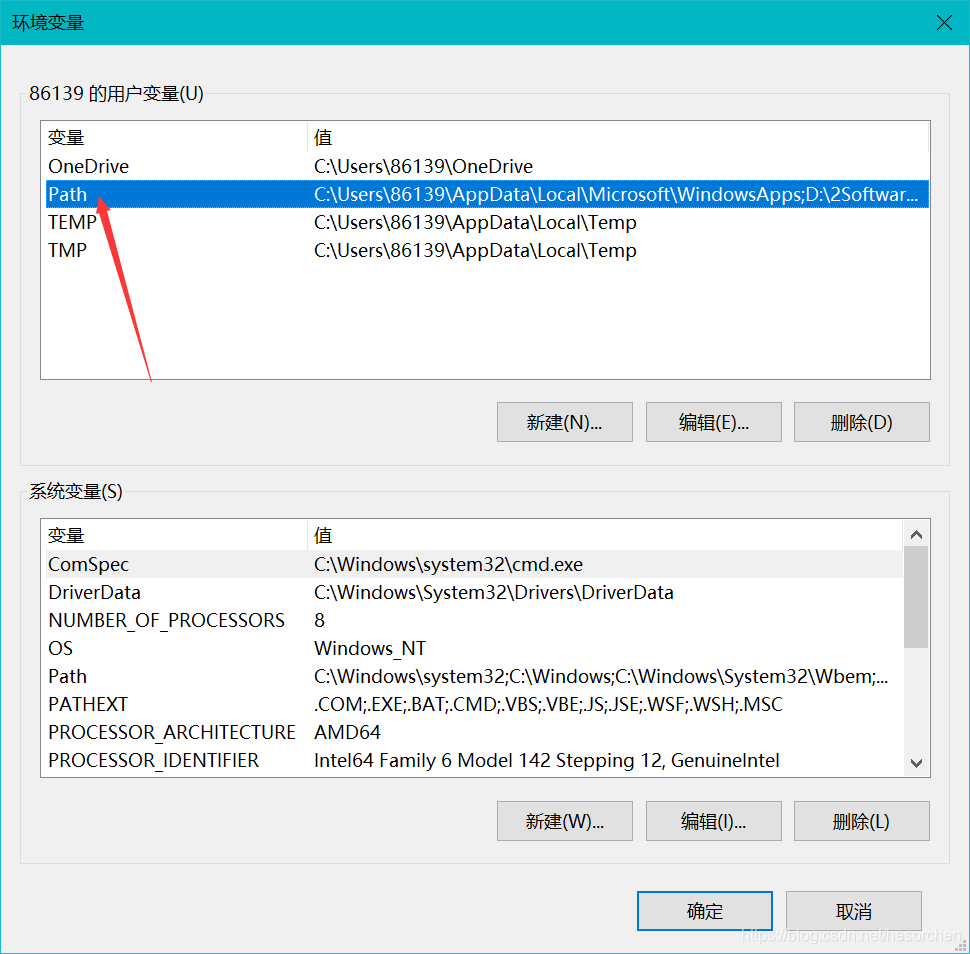
5.点击新建。
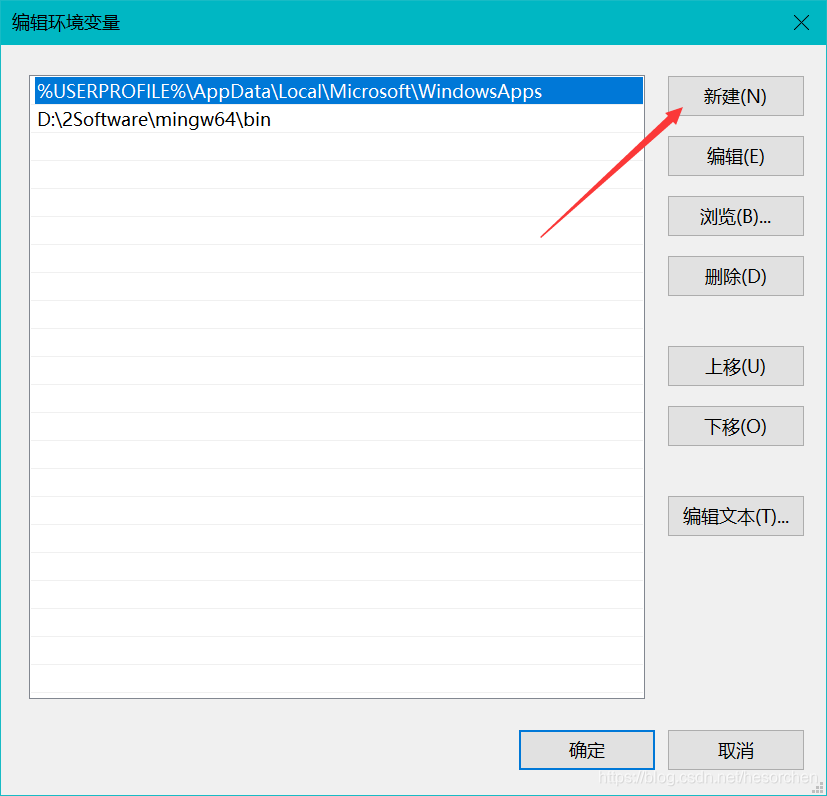
6.粘贴MinGW地址。
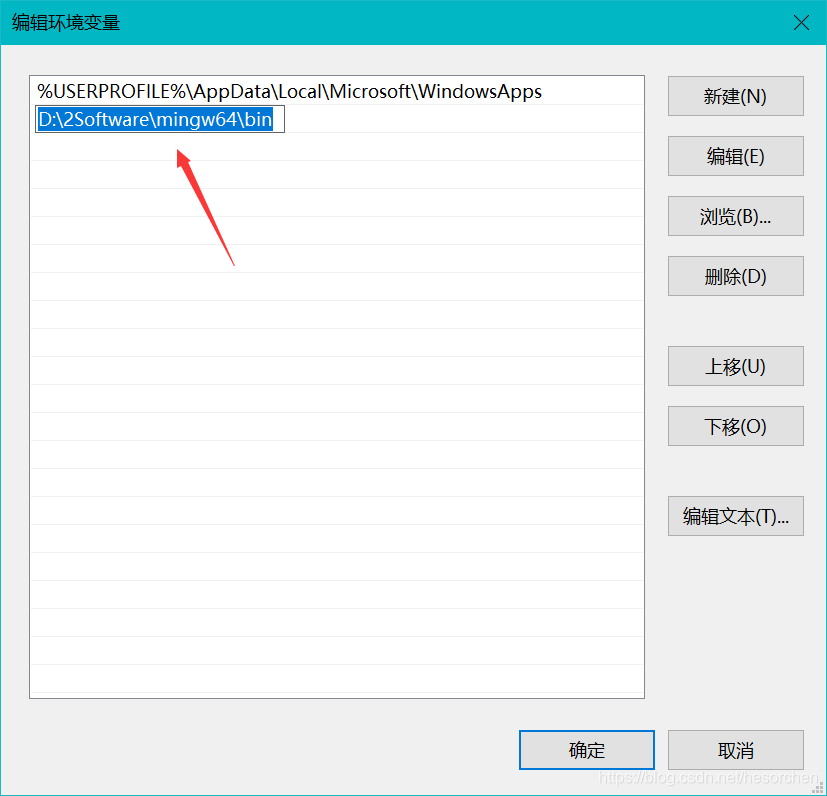
7.将刚才打开的而所有窗口按确定逐个退出。
到现在MinGW环境就算是配置好了,接下来可以验证一下是否配置成功:(如果失败的话确保步骤都正确,再试一次)
-
按下win+r,出现运行窗口,输入
cmd
-
输入g++,回车,会有两种反馈
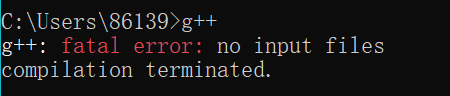
提示:'g++' 不是内部或外部命令,也不是可运行的程序或批处理文件。
第四步,打开vscode,点击扩展,先下载一个中文包。
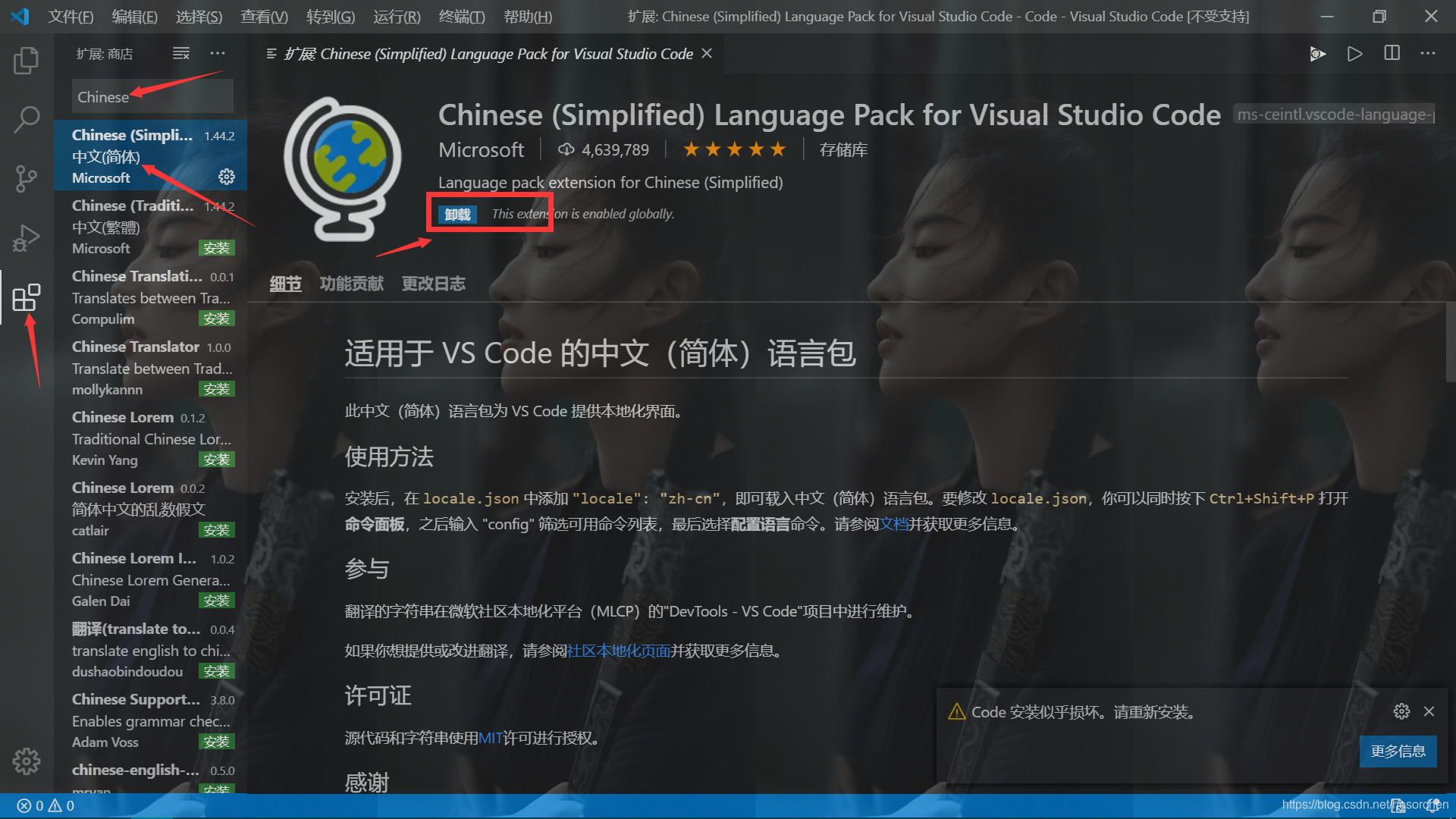
继续在扩展里边搜索C/C++插件并下载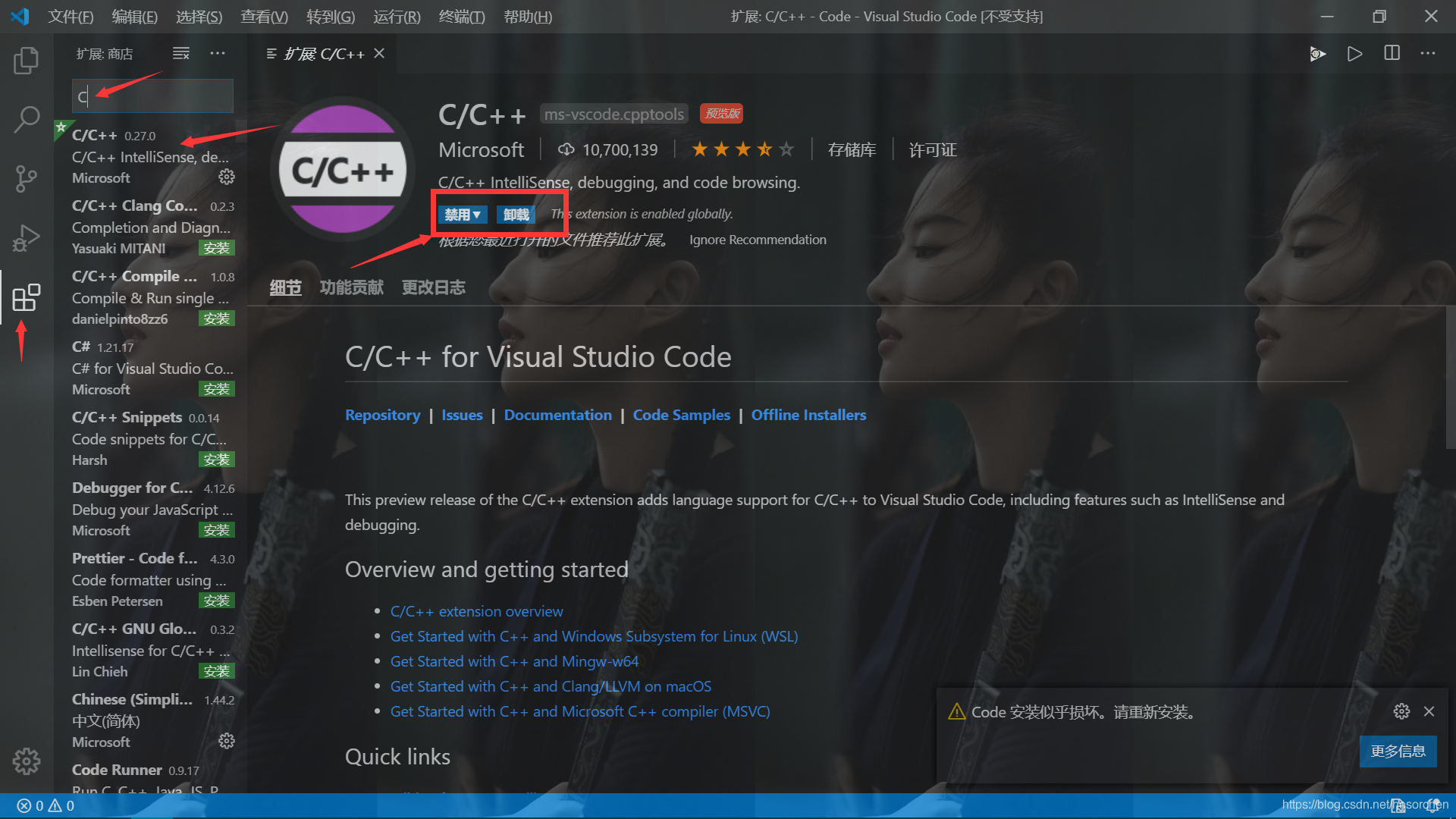
第六步,在你想要的位置新建一个code_test文件夹。然后打开vscode,打开这个文件夹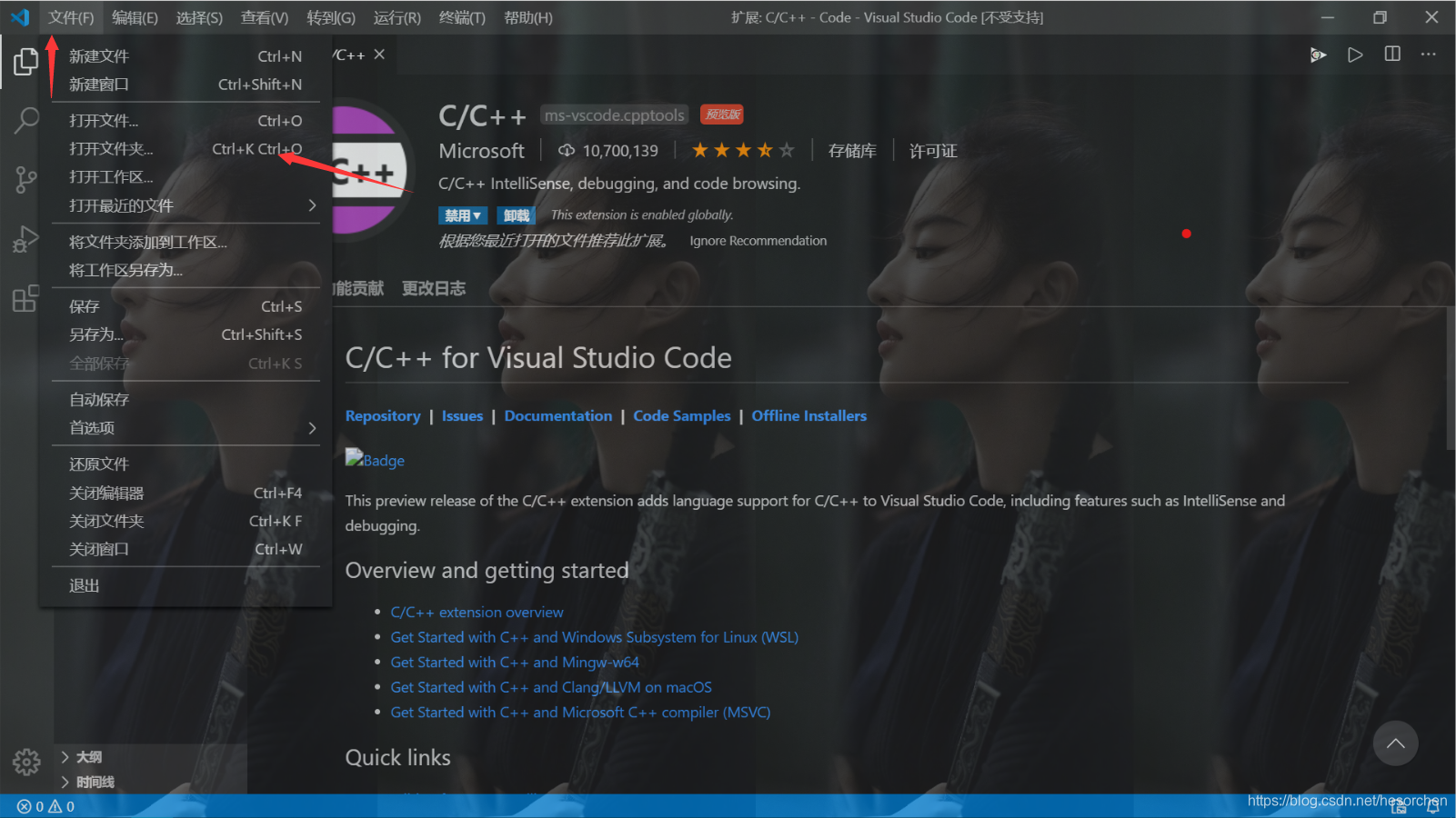
在code_test文件夹中新建一个 test.cpp文件
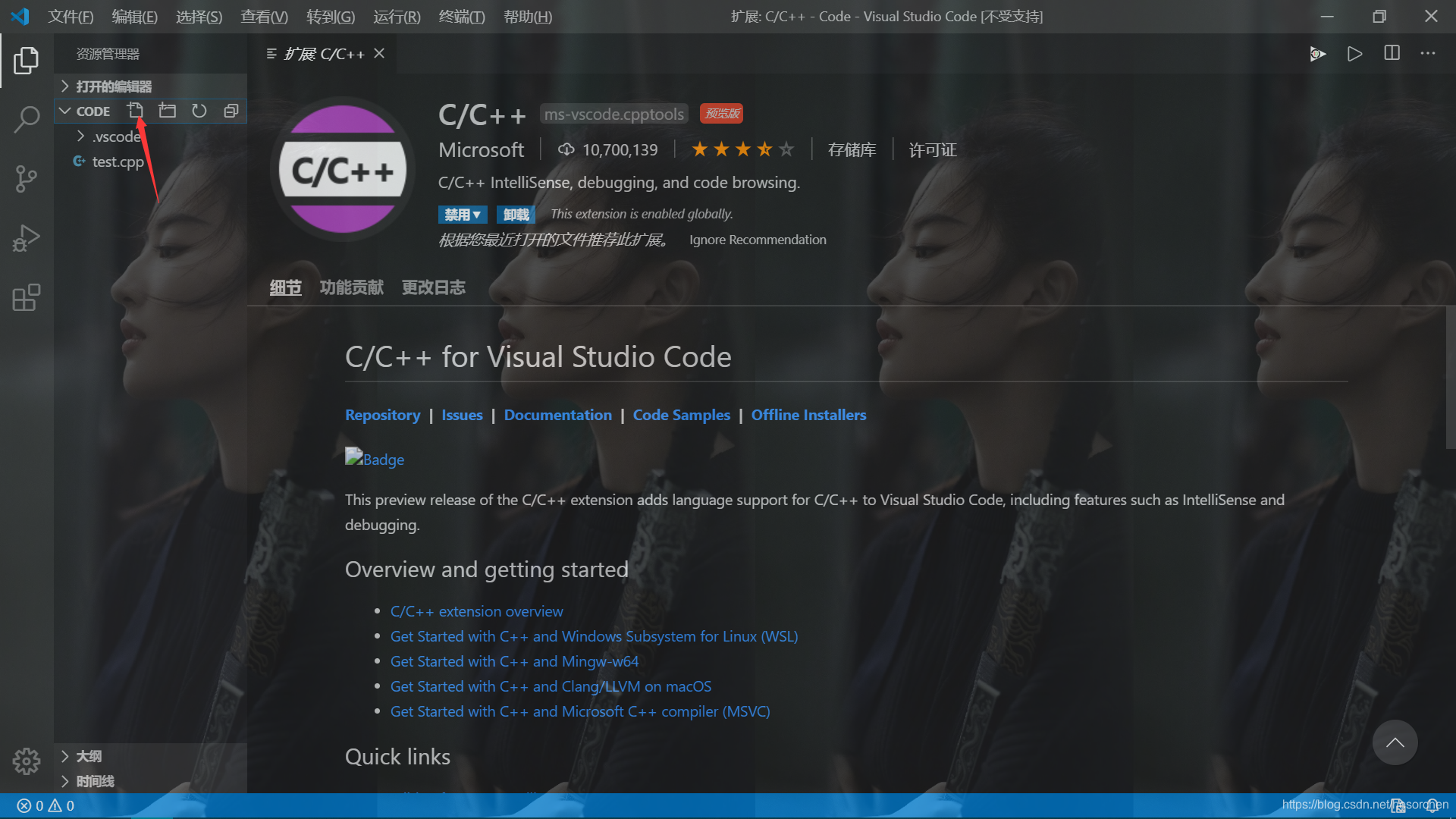
在test.cpp文件中输入一份简易的测试代码:
#include#include int main(){ printf("Hello VScode!\nHello C++\n"); system("pause"); return 0;}
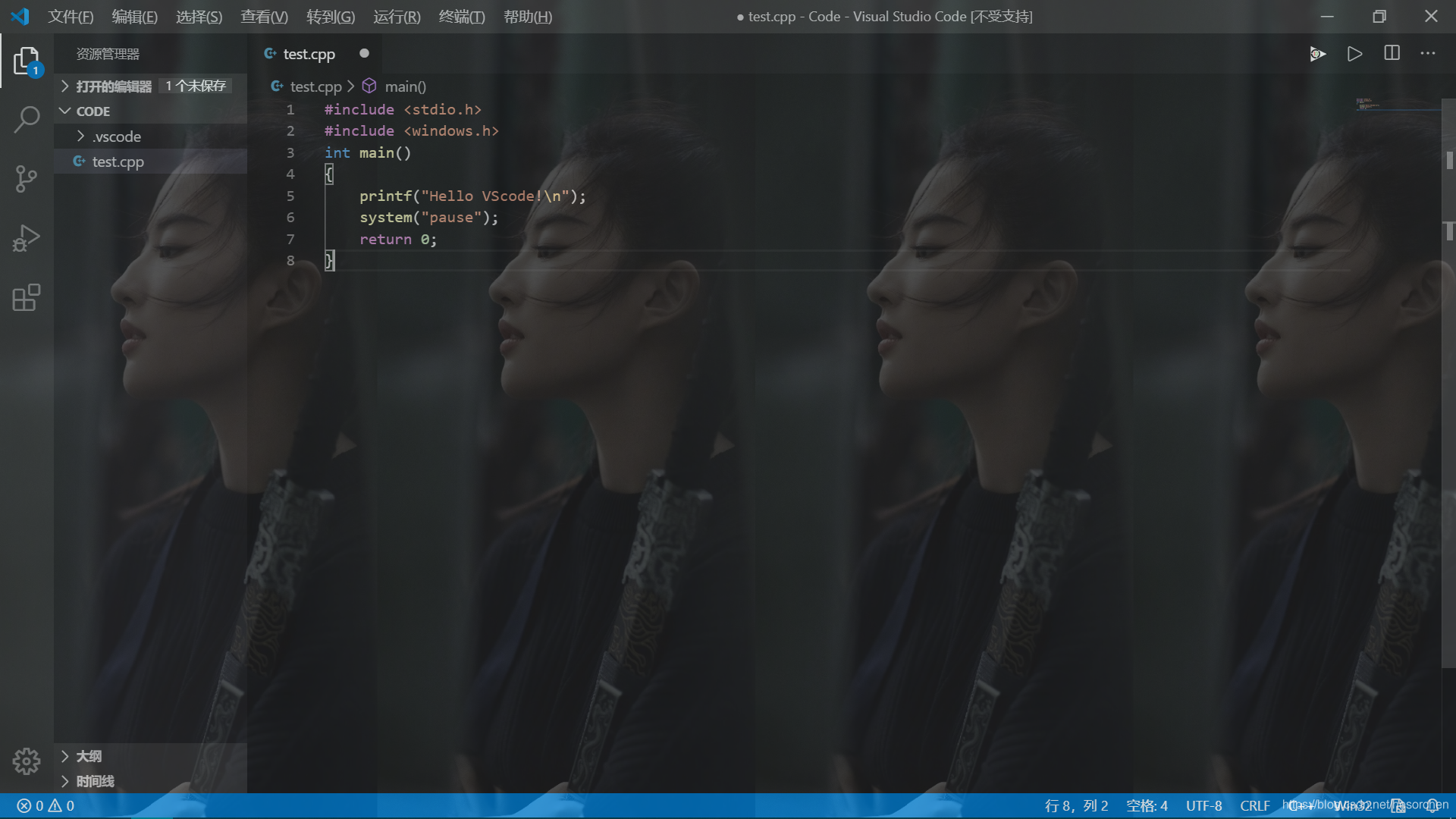
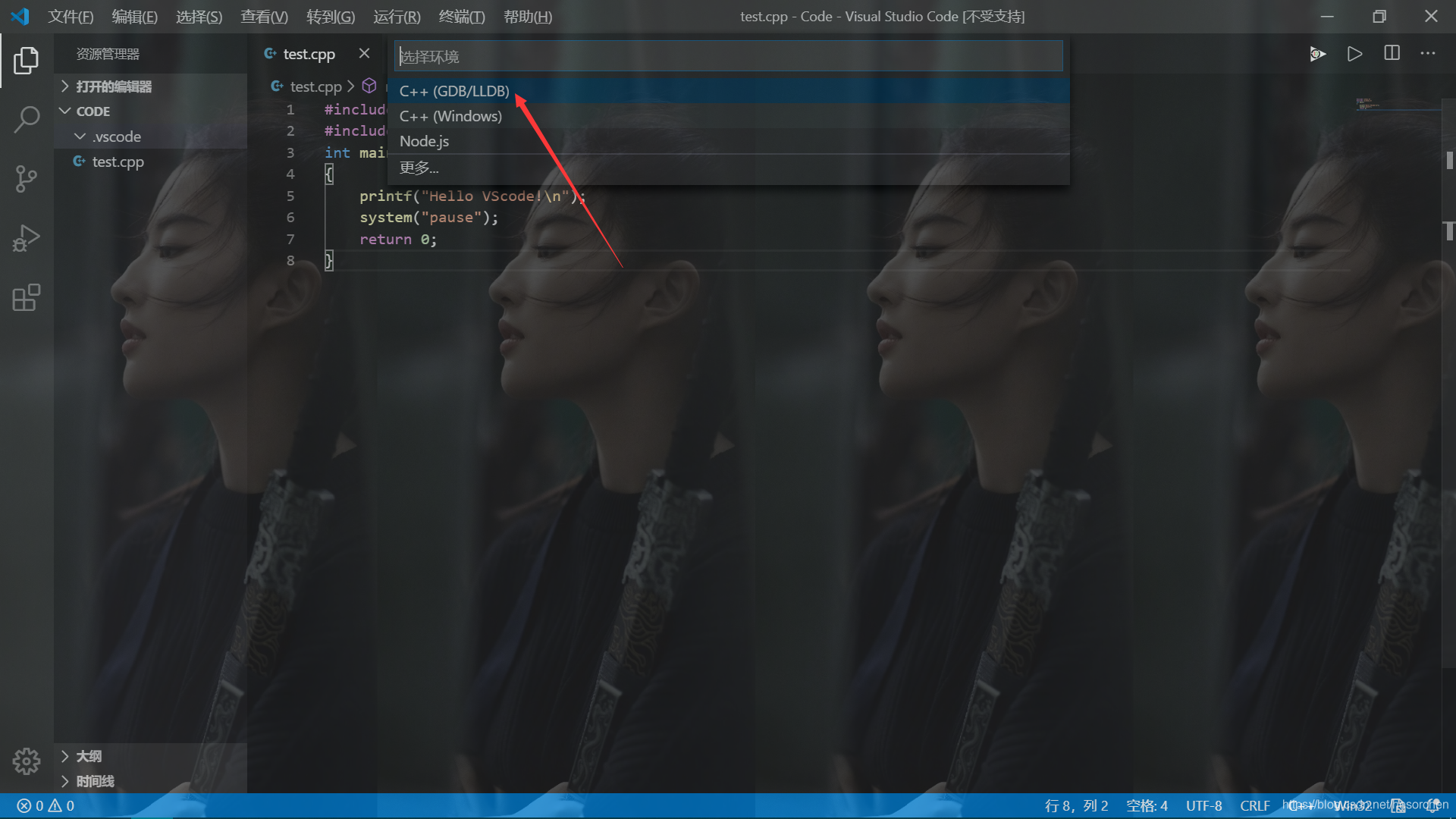
按下ctrl+F5,选择C++(GDB/LLDB),再选择g++.exe。
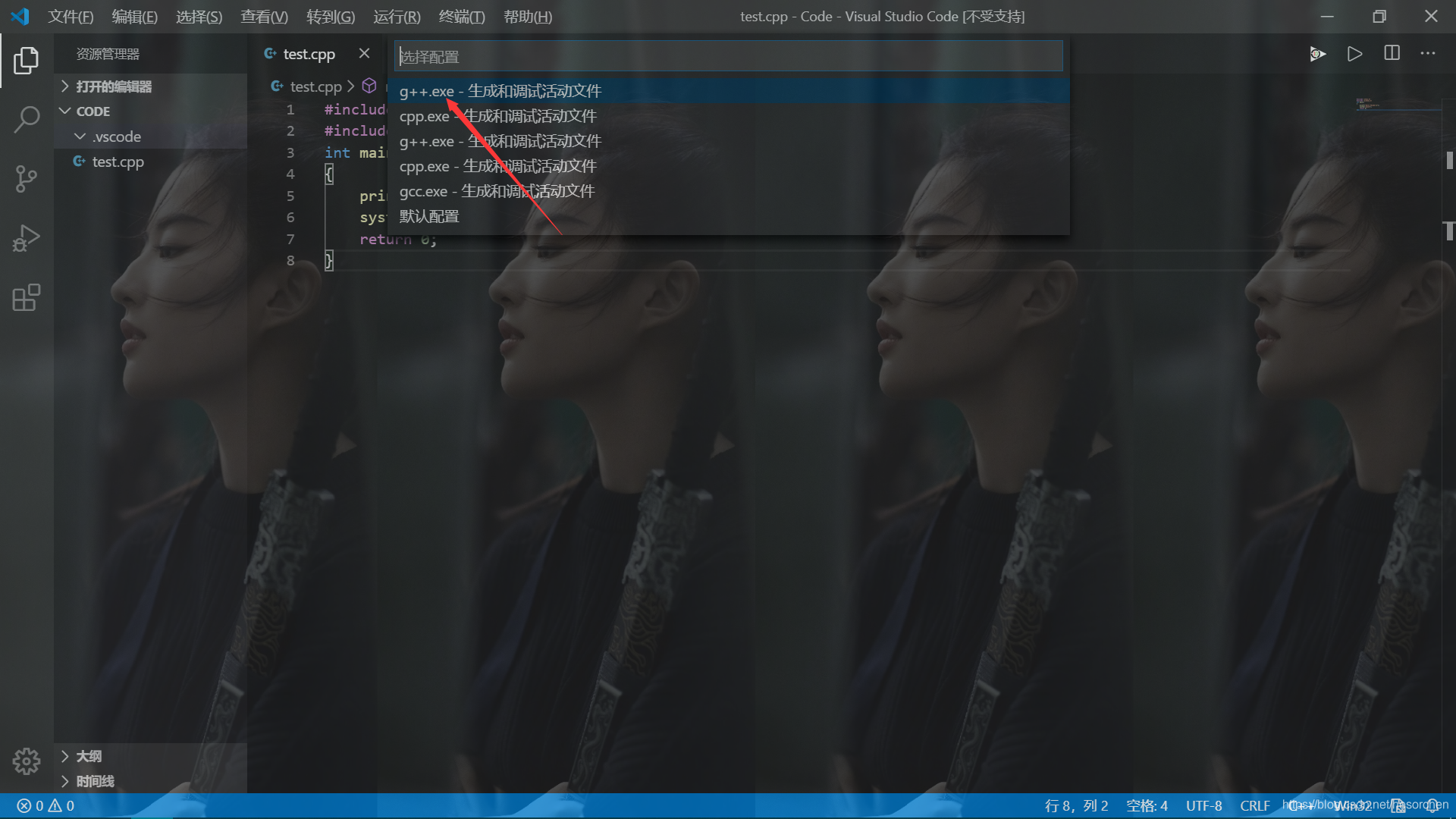
完成上述操作后,会出现launch.json文件,粘贴上下面的代码:
(除了"miDebuggerPath"需要改成MinGW的路径,其他应该可以不用改)
{ // 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。 // 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "g++.exe - 生成和调试活动文件", "type": "cppdbg", "request": "launch", "program": "${fileDirname}\\${fileBasenameNoExtension}.exe", "args": [], "stopAtEntry": false, "cwd": "${workspaceFolder}", "environment": [], "externalConsole": true,//小黑窗 "MIMode": "gdb", "miDebuggerPath": "D:\\2Software\\mingw64\\bin\\gdb.exe", "setupCommands": [ { "description": "为 gdb 启用整齐打印", "text": "-enable-pretty-printing", "ignoreFailures": true } ], "preLaunchTask": "g++.exe build active file" } ]} 回到test.cpp文件,按下ctrl+F5,应该会出现下图,点击配置任务,
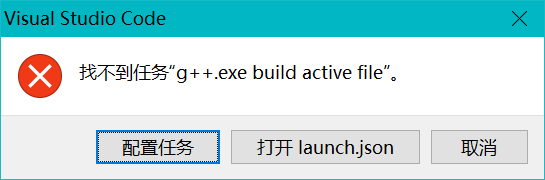
自动生成tasks.json文件,粘贴下面代码:
{ "tasks": [ { "type": "shell", "label": "g++.exe build active file", "command": "D:\\2Software\\mingw64\\bin\\g++.exe", "args": [ "-g", "${file}", "-o", "${fileDirname}\\${fileBasenameNoExtension}.exe" ], "options": { "cwd": "D:\\2Software\\mingw64\\bin" } } ], "version": "2.0.0"} 这时,我们返回到test.cpp文件,按下ctrl+F5,应该就可以正常编译运行了。
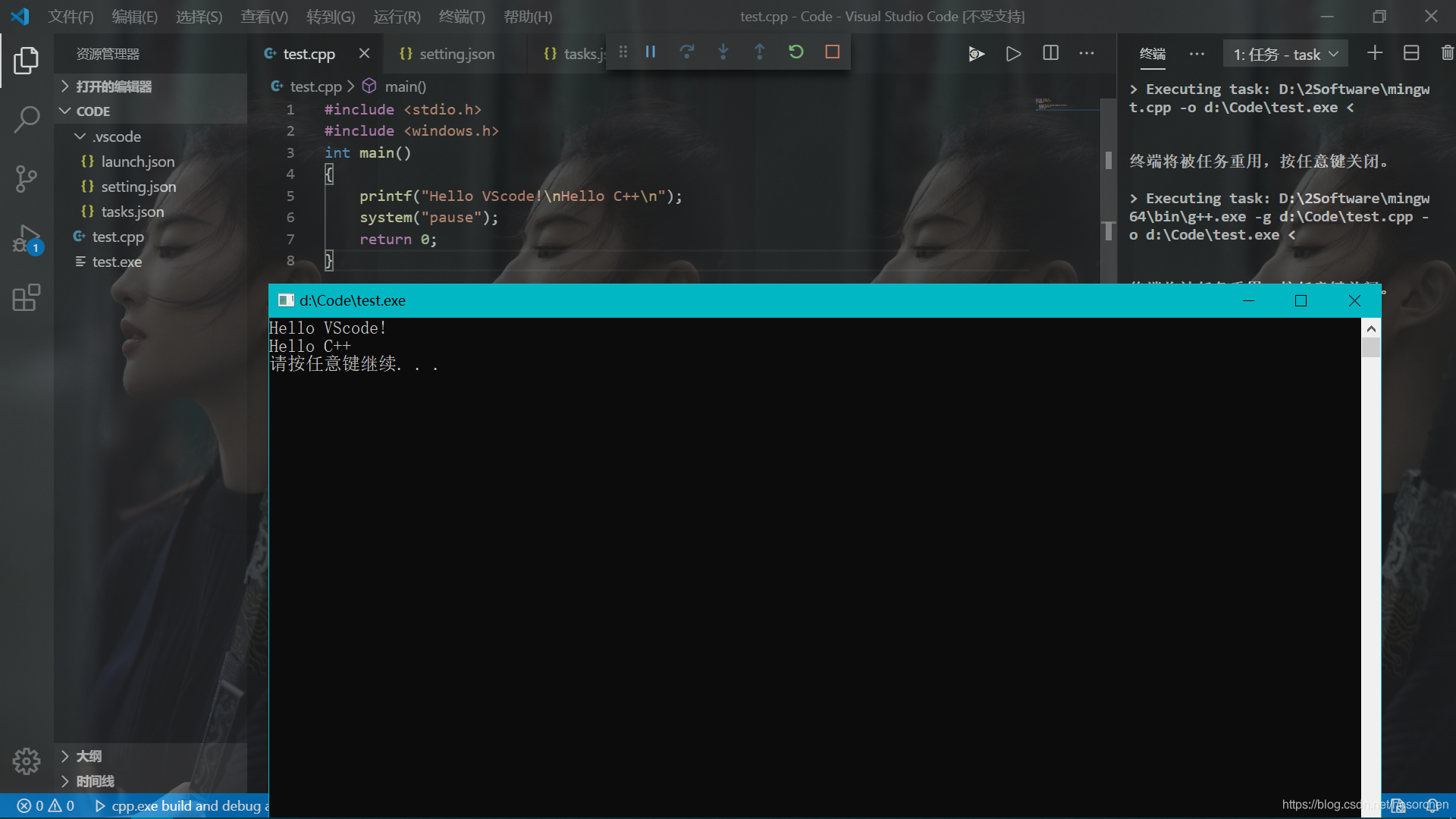
转载地址:http://ueod.baihongyu.com/
你可能感兴趣的文章
mysql problems
查看>>
mysql replace first,MySQL中处理各种重复的一些方法
查看>>
MySQL replace函数替换字符串语句的用法(mysql字符串替换)
查看>>
mysql replace用法
查看>>
Mysql Row_Format 参数讲解
查看>>
mysql select, from ,join ,on ,where groupby,having ,order by limit的执行顺序和书写顺序
查看>>
MySQL Server 5.5安装记录
查看>>
mysql server has gone away
查看>>
mysql skip-grant-tables_MySQL root用户忘记密码怎么办?修改密码方法:skip-grant-tables
查看>>
mysql slave 停了_slave 停止。求解决方法
查看>>
MySQL SQL 优化指南:主键、ORDER BY、GROUP BY 和 UPDATE 优化详解
查看>>
MYSQL sql语句针对数据记录时间范围查询的效率对比
查看>>
mysql sum 没返回,如果没有找到任何值,我如何在MySQL中获得SUM函数以返回'0'?
查看>>
mysql sysbench测试安装及命令
查看>>
mysql Timestamp时间隔了8小时
查看>>
Mysql tinyint(1)与tinyint(4)的区别
查看>>
MySQL Troubleshoting:Waiting on query cache mutex
查看>>
mysql union orderby 无效
查看>>
mysql v$session_Oracle 进程查看v$session
查看>>
mysql where中如何判断不为空
查看>>